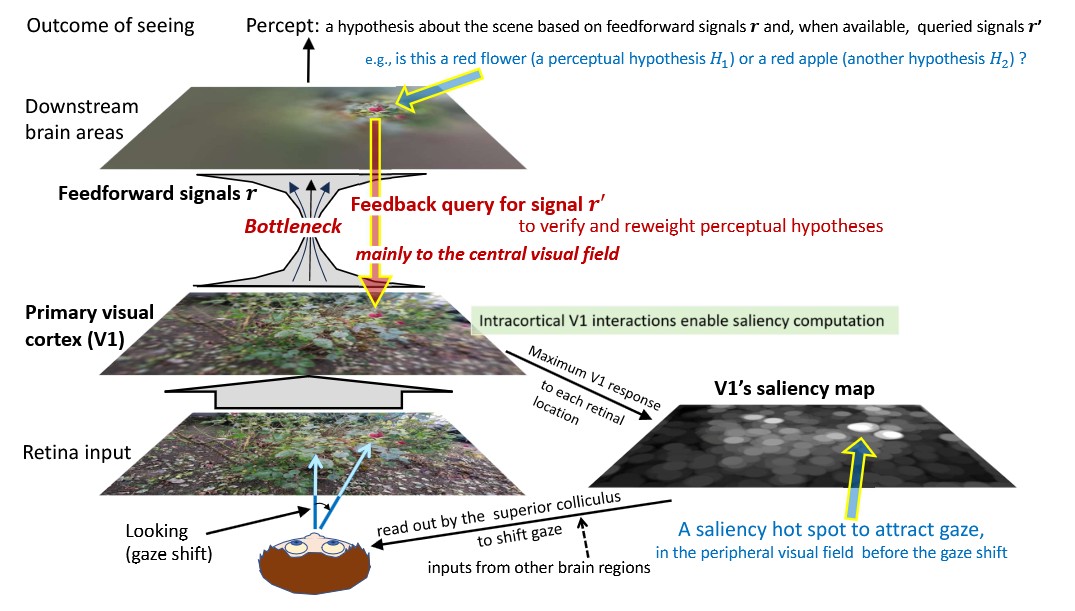
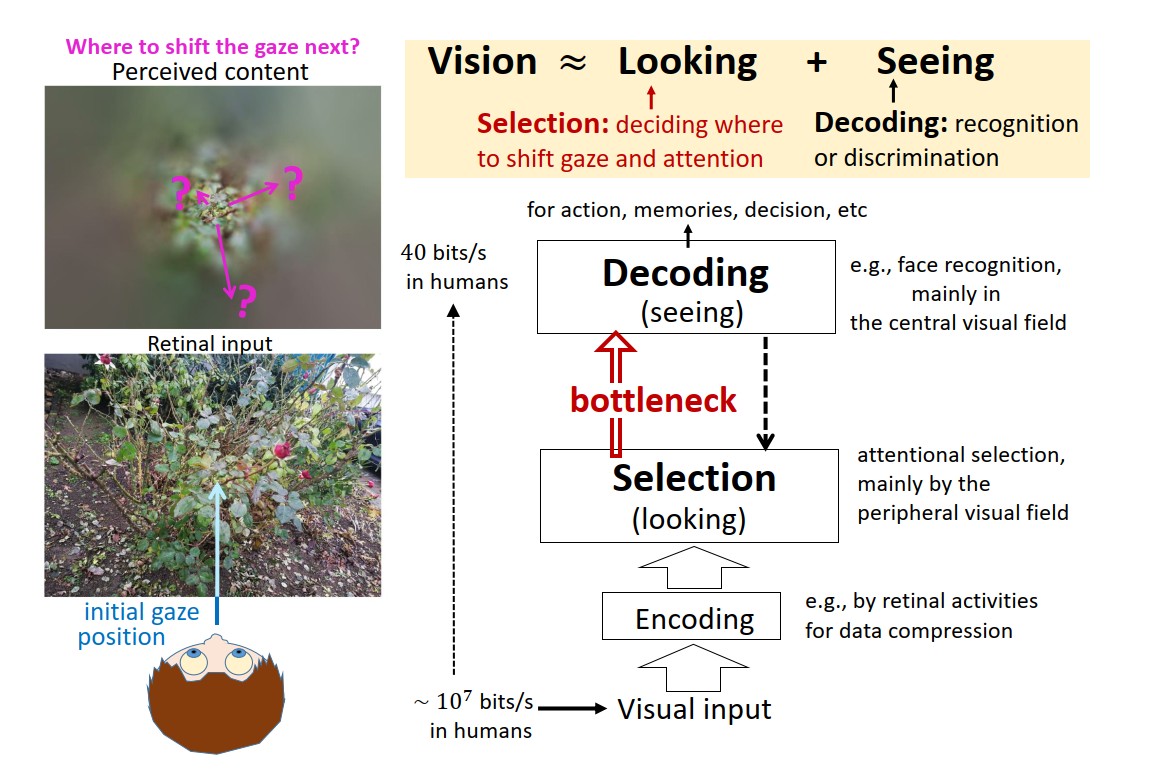
Progress in vision research has been slower downstream
than upstream of
primary visual cortex (V1). Traditional frameworks have
largely
overlooked a central constraint: only a tiny fraction of
retinal input
is recognized. Thus, to a first approximation, vision is
better
formulated as looking and seeing through a bottleneck.
Looking, mainly
by the peripheral visual field, selects visual information
to enter this
bottleneck, largely via gaze shifts that center selected
contents at
fovea. Seeing, mainly by the central visual field,
recognizes this
content. Converging evidence (see the paper below) suggests that V1 initiates
the bottleneck
and contributes to looking by generating a bottom-up
saliency map that
guides saccades exogenously, and that top-down feedback
along the visual
pathway, targeting mainly the representation of the
central visual
field, refines seeing. Progress will accelerate through
falsifiable
theories that explicitly link behavior with neural
substrates, and by
experimental designs that avoid forced fixation and
precisely track gaze.
Although Hubel and Wiesel established decades ago how individual V1 neurons transform retinal inputs, functions of V1 as a whole are being discovered only recently. First, V1 acts as a motor cortex for exogenously guiding saccades by constructing a bottom-up saliency map of the visual field. Second, V1 initiates a processing bottleneck: a massive reduction of visual information begins at its output to downstream areas. Third, downstream recognition is limited by impoverished information, V1 supports ongoing recognition by providing additional information queried by top-down feedback from downstream areas, directed predominantly to central visual field representations. These V1 functions underpin a framework in which vision is mainly looking and seeing through the bottleneck (see above).
Click here for the full paper